
Серверы баз данных DB2 UDB: основные особенности
DB2 UDB - это объектно-реляционная база данных, обладающая высокими показателями масштабируемости, расширяемости, простоты работы и управления.
Рассмотрим основные особенности DB2 UDB[6.6].
Масштабируемость - это возможность использовать один и тот же продукт (версии одного продукта) для задач различной сложности (например, для управления данными в масштабе отдела и в масштабе предприятия) с сохранением всей функциональности.
Масштабируемость в DB2 обеспечивается:
- расширенной параллельной обработкой;
- высокопроизводительной обработкой данных;
- эффективной работой с крупными базами данных.
В DB2 Universal Database параллельная обработка данных используется как для ускорения обработки транзакций, так и для ускорения обработки сложных запросов, а также для смешанных задач, включающих оба типа обработки. База данных поддерживает и параллельную обработку транзакций, и параллельную обработку сложных запросов на всех основных архитектурах аппаратных средств, включая симметричные мультипроцессорные системы (SMP), кластеры и системы с массовым параллелизмом (МРР) (рис. 6.12).
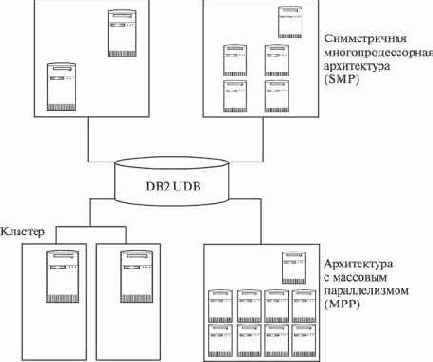
Рис. 6.12. Архитектуры аппаратных средств, поддерживаемые DB2 UDB
Параллельная обработка на SMP означает, что на машине с SMP UDB будет одновременно выполнять несколько транзакций (операторов SQL) параллельно, автоматически распределяя их между процессорами. Кроме того, UDB может выполнить параллельную обработку одного запроса (оператора SQL), разбивая его на подзадачи и направляя каждую подзадачу на свой процессор. Более того, если данные для оператора SQL распределены на нескольких дисковых подсистемах, то для параллельного извлечения данных в UDB будут использоваться функции параллельного ввода/вывода.
Поддержка кластеров и систем с массовым параллелизмом MPP означает, что база данных UDB может быть размещена на нескольких серверах в кластере или на нескольких узлах в системе с массовым параллелизмом. Несколько транзакций (операторов SQL) будут выполняться параллельно за счет автоматического распределения между несколькими узлами.
Кроме того, UDB может выполнить параллельную обработку одного запроса (оператора SQL), разбивая его на подзадачи и направляя каждую подзадачу на отдельный узел. Основой эффективных средств параллельной обработки с использованием нескольких узлов является интеллектуальное разделение и параллельная оптимизация. UDB автоматически разделяет (распределяет) данные между несколькими узлами, причем оптимизатор передает обработку тому узлу, на котором находятся нужные данные, сокращая до минимума пересылку данных между узлами.
Помимо расширенной параллельной обработки DB2 UDB, так же, как ряд других современных баз данных, поддерживает другие важные функции высокопроизводительной обработки данных, которые значительно повышают производительность как обработки сложных запросов, так и обработки транзакций. Благодаря этим и прочим функциональным возможностям DB2 UDB особенно хорошо подходит для работы со смешанными задачами (в которых имеют место и транзакционная обработка, и обработка сложных запросов).
К средствам повышения производительности следует также отнести:
- Поддержку 64-разрядной памяти. В настоящее время в системе дополнительно реализована поддержка очень больших объемов физической памяти (64-разрядной). В DB2 применяются 64-разрядные и 32-разрядные системы, позволяющие работать более чем с 4 Гбайт физической памяти. С помощью буферного пула в этой дополнительной памяти можно хранить используемые в настоящий момент данные, благодаря чему значительно сокращается количество операций ввода/вывода и повышается производительность;
- Асинхронная очистка страниц. Возможность переложить операции записи буферизованных страниц с задачи выполнения запроса SQL на другую задачу позволяет значительно сократить время отклика системы на запросы. Задачи асинхронной очистки страниц обеспечивают наличие достаточного свободного пространства в буферах базы данных для обработки данных запроса. Эта функция позволяет при обработке запроса избежать ожидания синхронной записи модифицированных страниц из буфера на диск для освобождения места под данные запроса;
- Расположение табличных областей на нескольких носителях.
Кроме того, с ее помощью можно создавать индексы и собирать статистические данные в процессе загрузки. Утилита LOAD может значительно сократить время, необходимое для обновления или добавления данных; - в DB2 UDB архитектура симметричных мультипроцессорных систем (SMP) применяется не только при обработке транзакций и запросов, но и при работе с утилитами. Это обеспечивает возможность параллельной загрузки данных, параллельного создания индексов, параллельного резервного копирования и восстановления;
- при работе с утилитами в DB2 UDB могут использоваться преимущества кластерных архитектур и архитектур с массовым параллелизмом. Основой для работы систем с массовым параллелизмом является интеллектуальное разделение. Данные перед загрузкой можно разбить на разделы. После этого их можно загружать параллельно на нескольких узлах, что значительно сокращает общее время процесса загрузки. После разделения данных утилиту LOAD можно запустить параллельно на всех узлах. Параллельно на всех узлах системы может выполняться команда создания индекса CREATE INDEX. Аналогично операции резервного копирования и восстановления также могут выполняться на нескольких узлах параллельно.
Благодаря всем этим расширенным функциям параллельной обработки, средствам высокопроизводительной обработки и возможностям эффективной работы с крупными базами данных DB2 Universal Database является наиболее масштабируемой объектно-реляционной базой данных с поддержкой Web.
Расширяемость - это возможность управлять не только данными, организованными с помощью реляционных таблиц с символами и числами, но и мультимедийными данными, комплексными объектами, такими как изображения, аудио, видео, пространственные данные, временные ряды и т.д. В эту категорию могут входить и такие объекты, как рентгеновские снимки, отпечатки пальцев, конструкторские чертежи и т.д. Технологии хранения таких данных в СУБД реляционного типа называют объектно-реляционными. Объектно-реляционные возможности позволяют добавлять к базе данных собственные типы данных, настраивая базу на конкретные требования.
Большие двоичные объекты можно использовать для хранения мультимедийных данных, таких как документы, видео, изображения и речь. Кроме того, большие объекты можно использовать для хранения некрупных структур, семантика которых задана с помощью пользовательских типов UDT и пользовательских функций UDF. Для больших объектов LOB имеется мощный набор встроенных функций для выполнения поиска, выделения подстроки и конкатенации. С помощью UDF в любое время можно определить дополнительные функции. Таблица может содержать несколько столбцов с большими объектами LOB (см. рис. 6.13).
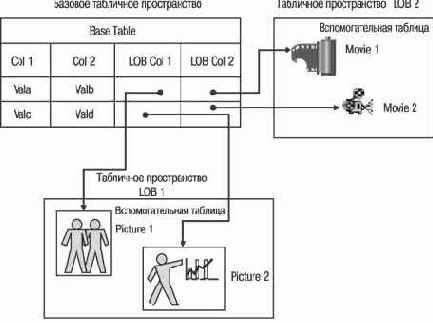
Рис. 6.13. Хранение больших объектов (LOB)
Определяемые пользователем табличные функции (Table UDF) - пользователи могут теперь обращаться средствами SQL к данным, хранящимся не в реляционном формате, и при этом в полной мере использовать все возможности построения запросов реляционной базы данных. Часто возникают трудности, если невозможно включить данные из нереляционных источников в реляционную обработку. Определяемые пользователем табличные функции представляют собой расширение SQL, позволяющее решить эту проблему. Табличная функция представляет собой внешнюю определяемую пользователем функцию, которая создает производную таблицу. Программа этой функции может включать в себя обращение к данным из различных источников и преобразование их в табличную форму, возвращаемую этой табличной функцией. После создания табличной функции ее можно использовать в операторах FROM запросов.
Путем расширения деловых правил обеспечивается целостность хранящихся в базе данных. Эти правила дополнительно расширяют прочие объектно-ориентированные функции. С их помощью можно расширить существующие только в виде кода объектные библиотеки (методы которых изменить невозможно) для поддержки дополнительных атрибутов объектов и проверки ограничений. Ключевые возможности деловых правил включают в себя:
- значения по умолчанию - позволяют устанавливать значения по умолчанию для тех строк, которым в операторах INSERT непосредственных значений не присваивается;
- проверка ограничений - используется для введения деловых правил, которые невозможно реализовать с помощью ограничений на уникальность ключей или ссылочной целостности.
Расширения DB2 Extenders строятся на основе объектно- реляционной инфраструктуры DB2. Каждое расширение представляет собой набор предопределенных пользовательских типов данных UDT, пользовательских функций UDF, триггеров, ограничений и хранимых процедур, решающих задачи конкретной прикладной области. С помощью расширений пользователи могут хранить в таблицах DB2 текстовые документы, изображения, видео- и аудиоролики путем добавления столбцов с новыми типами данных, определенными в расширении. Сами данные могут храниться как внутри таблицы, так и вне ее во внешних файлах. Кроме того, эти новые типы данных имеют атрибуты, описывающие различные аспекты их внутренней структуры, такие как, например, <язык> и <формат> для текстовых данных. Каждое расширение включает в себя необходимые функции для создания, обновления, удаления и поиска данных с новыми типами, определенными в расширении. Пользователи могут включать эти новые типы данных и функции в операторы SQL, обеспечивая интегрированный поиск по содержимому для всех типов данных.
В таблице 6.1 приведены основные компоненты IBM DB2 UDB, указано их назначение и основная функциональность.Таблица 6.1. Компоненты IBM DB2 UDB
№ п/п Название компонентаНазначение Основная функциональность 1. DB2 XML Extender Обеспечение работы с XML-документами - сохранение XML-документов;
- разработка XML-документов;
- преобразование данных в XML-документ;
- текстовый поиск в XML-документе (с использованием DB2 Text Extender)
2. DB2 Net Search Extender Текстовый поиск в Internet из базы данных Высокоскоростной и масштабируемый текстовый поиск в Internet из базы данных 3. DB2 OLAP Starter Kit Поддержка онлайновых аналитических процедур (в отсутствие OLAP-сервера) Создание сложных аналитических приложений (при отсутствии OLAP-сервера) 4. DB2 UDB2 Text Information Extender Поиск по текстовым документам - быстрый поиск по текстовым документам на основе SQL-запросов;
- поддержка форматов HTML и XML;
- объединение в одном продукте функций DB2 Text Extender и DB2 Net Search Extender
5. DB2 Spatial Extender Обработка пространственных данных Хранение, доступ, управление и выполнение операций анализа пространственных данных в той же базе, где хранятся бизнес-данные и осуществляется визуализация результатов запросов 6. DB2 Data Links Manager Управление внешними данными (находящимися за пределами базы данных) - доступ к внешним данным, находящимся в файлах внешней операционной системы, HTML, XML и изображениях;
- управление внешними данными (доступ, резервирование, восстановление);
- контроль целостности внешних данных
7. DB2 Relational Content Доступ к базам данных ORACLE - повышение производительности при чтении баз данных ORACLE (при совместном использовании приложением DB2 и ORACLE);
- поддержка приложений и масштабируемой коммуникационной инфраструктуры для работы Web-приложений, приложений для Windows, UNIX, Linux и OS/2 с данными S/390 и AS/400
8. DB2 Audio Extender Работа с аудио-информацией - импорт и экспорт аудиофрагментов и атрибутов аудио-информации;
- защита и восстановление аудиоданных;
- поиск и проигрывание аудиофрагментов;
- поддержка широкого диапазона форматов аудиофайлов (WAVE, MIDI, MPEG 1, AU), работа с различными аудиосерверами
9. DB2 Image Extender Работа с изображениями - импорт и экспорт изображений и их атрибутов;
- контроль доступа и преобразование форматов изображений;
- защита и восстановление изображений;
- поиск и просмотр изображений;
- создание уменьшенных версий изображений
10. DB2 Video Extender Обработка видеоинформации - импорт и экспорт видеофрагментов и их атрибутов;
- защита и восстановление видеоданных;
- поиск и проигрывание видеофрагментов;
- раскадровка видеоданных (выявление точек <смены сцены>, в которых имеет место существенное различие между двумя следующими друг за другом кадрами, запись соответствующих данных и репрезентативных кадров);
- поддержка широкого спектра форматов видеофайлов, включая MPEG1, MPEG2, AVI, QuickTime;
- работа с различными видеосерверами
В UDB администраторы базы данных могут разделить базу данных на части, называемые табличными областями (tablespaces). При создании таблицы можно определить имена базовой (base), индексной (index) и длинной (long) табличной области. Использование индексных и длинных табличных областей позволяет хранить индексы и большие объекты (LOB) отдельно от остальных табличных данных. Благодаря такой гибкости повышается производительность и готовность базы данных. Табличные области могут охватывать одно или несколько физических запоминающих устройств, то есть располагаться на нескольких носителях; - Непосредственный доступ к носителям (работа с устройствами напрямую). UDB позволяет непосредственно работать с данными на устройстве, не тратя ресурсы на использование файловой системы, что повышает производительность базы данных. Администратор имеет возможность определить для табличной области режим непосредственной работы с устройством или использовать обычную файловую систему полностью совместимым с предыдущими версиями методом;
- Чтение больших блоков. Данная функция позволяет считывать несколько дисковых страниц за одну операцию ввода/вывода, что уменьшает нагрузку на центральный процессор и, соответственно, сокращает время отклика.
Масштабируемость включает в себя гораздо больше, нежели просто ускорение обработки транзакций и сложных запросов за счет параллельной обработки или других средств повышения производительности. Масштабируемыми должны быть и обслуживающие операции, такие как загрузка данных, резервное копирование и восстановление, генерация индексов. В DB2 UDB это достигается с помощью следующих средств:
- DB2 UDB включает высокоскоростную утилиту загрузки LOAD, с помощью которой можно значительно повысить скорость загрузки данных, обеспечив при этом их восстанавливаемость. Эта утилита может принимать данные в различных файловых форматах и непосредственно создавать страницы табличных областей, не затрачивая ресурсы на работу с контрольным журналом и обработку операторов SQL INSERT.
Расширения в DB2 UDB можно разделить на три группы:- использование сложных типов данных;
- расширение деловых правил;
- расширение SQL;
- расширения DB2 Extenders.
К сложным типам данных относятся определяемые пользователем типы данных, определяемые пользователем функции, большие объекты.
Определяемые пользователем типы данных (UDT). С их помощью пользователи могут создавать новые типы данных, которые будут представлены в базе данных с использованием встроенных типов. Например, пользователь может определить два типа данных для валют: CDOLLAR для канадских долларов и USDOLLAR - для долларов США. Эти типы будут различаться в том смысле, что их невозможно будет непосредственно сравнивать друг с другом или с десятичным (decimal) типом, хотя именно десятичный тип может быть выбран для внутреннего представления этих двух типов данных в DB2. Определяемые пользователем типы данных, как и встроенные типы, могут применяться в качестве столбцов таблиц или параметров функций, включая определяемые пользователем функции (User-Defined Functions, UDF). Например, пользователь может определить тип данных ANGLE (угол, значения которого могут находиться в пределах от 1 до 360) и создать собственные функции для работы с этим типом, такие как SINE (вычисление синуса), COSINE (вычисление косинуса) и TANGENT (вычисление тангенса).
Определяемые пользователем функции (UDF). С их помощью в запросы можно включать мощные вычислительные предикаты и предикаты поиска для фильтрации данных непосредственно у их источника. Благодаря UDF пользователи могут создавать наборы функций для работы с пользовательскими типами данных, определив таким образом семантику этих типов. Поддержка UDF позволяет создавать библиотеки функций, причем их разработкой может заниматься IBM, независимые поставщики или сами заказчики, и затем встраивать их непосредственно в базу данных.
Большие объекты (LOB). С помощью больших объектов (LOB) пользователи могут хранить в базе данных очень крупные двоичные или текстовые объекты (размером в несколько гигабайт).
Например, пользователь может ввести ограничение на таблицу данных о служащих EMPLOYEE, чтобы должность сотрудника могла принимать только одно из значений 'Sales', 'Mqr', или 'Clerk' и чтобы заработная плата сотрудника, проработавшего в компании более 8 лет, составляла более 40 000 долларов; - ссылочная целостность - позволяет устанавливать необходимые взаимосвязи между таблицами и внутри таблиц. Ссылочные ограничения объявляются при создании таблицы и обеспечивают согласованность значений данных между связанными столбцами различных таблиц. DB2 автоматически будет поддерживать эти взаимосвязи, так что разработчикам не придется программировать соответствующие функции в приложении;
- триггеры - можно использовать для реализации комплексных межтабличных деловых правил, автоматической генерации значений для новой добавленной строки, считывания данных из других таблиц в целях обеспечения ссылочной целостности, записи в другие таблицы в целях генерации контрольного журнала и/или реализации функции уведомления за счет создания триггера, запускающего определяемую пользователем функцию (например, отправки сообщения электронной почты). Например, пользователь может создать триггер, который будет увеличивать на единицу количество пользователей при каждом добавлении строки в таблицу служащих EMPLOYEE.
Расширение SQL позволяет включать в один непроцедурный оператор большой объем операций по обработке данных. В качестве примеров можно привести рекурсивные запросы SQL. Использование рекурсивных запросов делает возможными, например, такие запросы:
- запросы по ведомости материалов, когда пользователь желает узнать все составные компоненты какой-либо детали, все составные компоненты этих компонентов и т.д.;
- запросы с расчетами по выбору маршрута, когда пользователь желает определить самый выгодный с точки зрения тарифов маршрут перелета с несколькими пересадками. С помощью рекурсивного SQL может быть, к примеру, сформулирован следующий запрос: определить все возможные варианты перелета из Торонто в Хабаровск без пересадок и не более чем с тремя пересадками.